
ID(プライマリーキー)の採番方法については、主にSequential(auto increment)とUUIDv4の2つの方法があります。
UUIDはセキュリティ面などでの利点がありますが、生成が時系列順ではなくB-treeとの相性が悪いためパフォーマンスに問題があることがあります。
そのため、タイムスタンプ情報を用いて時系列順に採番できるUUIDv6、UUIDv7、UUIDv8がIETFによって提案されています。
v6はタイムスタンプがグレゴリオ暦ベース、v7はUnix Time Stampベース、v8は独自仕様ということですので、特に理由がなければv7を使うのが良さそうです。
また、同様に時系列順に採番できるものとしてULIDがオープンソースで公開されています。
今回は、Sequential、UUIDv4、UUIDv7、ULIDの4つについてPostgresSQLでパフォーマンスを測定してみました。
各ID生成方法の概要
画像はこちらから引用しました。
Sequential
特徴
- 数値の連番
メリット
- 時系列順のためデータ格納時にB-treeとの相性が良い。そのため、パフォーマンスが良い
- insertの効率が良い
- selectも現実では時系列に相関がある形でクエリが発行されることが多いので、Sequentialの方が効率が良いことがある
UUIDv4
特徴
- 128ビットの数値で、内6ビットがversion/variant(UUIDの種類)、122ビットがランダムな数値

メリット
- 推測不可能なため、URLなどでIDを外部に晒す場合はセキュリティの向上を見込める
- 各DBノードで自律的にIDを発行できるので、クラスタ構成時にキーの衝突を考慮する必要がない
- キーを事前に決定できるので、シャーディング時にロジックが簡潔になる
UUIDv7
特徴
- 128ビットの数値で、内48ビットがtimestamp、6ビットがversion/variant(UUIDの種類)、12ビットが単調増加の数値、62ビットがランダムな数値
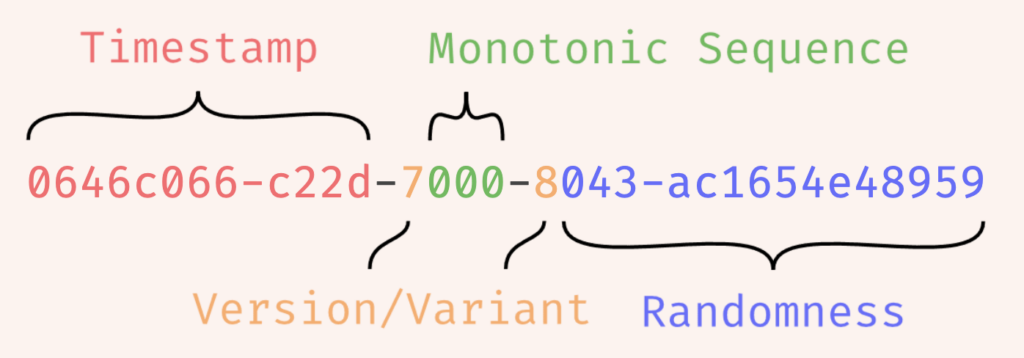
メリット
- 発行されるIDが時系列順なので、UUIDv4に比べてパフォーマンスの改善が期待できる
ULID
特徴
- 128ビットの数値で、内48ビットがtimestamp、80ビットがランダムな数値
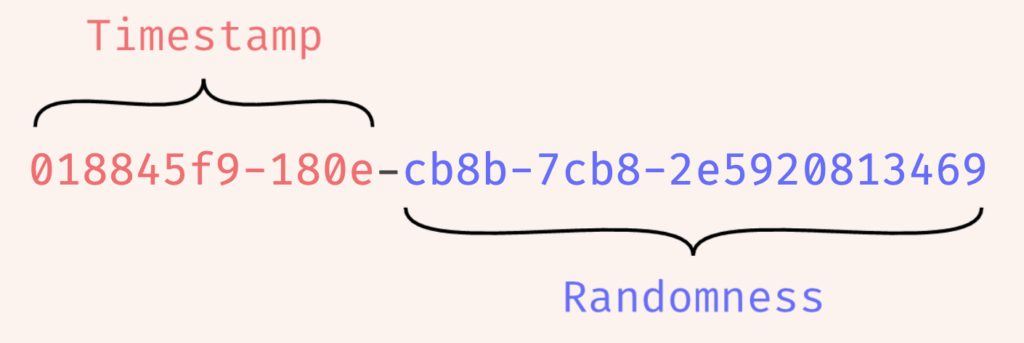
メリット
- 発行されるIDが時系列順でUUIDv7と似たコンセプトだが、UUIDv7より優れている(参考)
- UUIDv7のようにversion/variantや単調増加する数値を公開しない
- UUIDv7よりもランダム値の桁数が多い
- UUIDv7よりも構造がわかりやすい
実験方法
環境
OS: Ubuntu 20.04.6 LTS CPU: Intel(R) Xeon(R) CPU E5-2676 v3 @ 2.40GHz Core: 1 Mem: 1GB PostgreSQL: 12.14 (Ubuntu 12.14-0ubuntu0.20.04.1)
データ
データベースの構造は以下になります。
ユーザ一覧テーブル、ブログ記事一覧テーブル、両者の交差テーブルがあります。
-- Sequential
CREATE TABLE users (
id int PRIMARY KEY,
name VARCHAR(100) NOT NULL,
age int NOT NULn
);
CREATE TABLE articles (
id int PRIMARY KEY,
title VARCHAR(100) NOT NULL,
body TEXT NOT NULL
);
CREATE TABLE user_article_relations (
id int PRIMARY KEY,
user_id int REFERENCES users(id) NOT NULL,
article_id int REFERENCES articles(id) NOT NULL
);
-- UUIDv4, UUIDv7, ULID
CREATE TABLE users (
id UUID PRIMARY KEY,
name VARCHAR(100) NOT NULL,
age int NOT NULL
);
CREATE TABLE articles (
id UUID PRIMARY KEY,
title VARCHAR(100) NOT NULL,
body TEXT NOT NULL
);
CREATE TABLE user_article_relations (
id UUID PRIMARY KEY,
user_id UUID REFERENCES users(id) NOT NULL,
article_id UUID REFERENCES articles(id) NOT NULL
);計測方法
計測にはpgbenchコマンドを使用しました。
pgbench -c 3 -t 1000 -f ファイル名 -U ユーザ名 -h 127.0.0.1 -p 5432 -d データベース名c: コネクション数
t: トランザクション数
INSERTは何度も実行できないため、「-c 1 -t 1」で測定しています(実質1度きりの測定)。
SELECT, JOINに関しては「-c 3 -t 1000」で測定しています。
これは3人のユーザから同時にアクセスがあり、それぞれのユーザに対して1000件ずつトランザクションが走るようなシミュレーションになります。
実行すると以下が出力されます。
transaction type: ./sql_files/join/ulid.sql scaling factor: 1 query mode: simple number of clients: 3 number of threads: 1 number of transactions per client: 1000 number of transactions actually processed: 3000/3000 latency average = 205.517 ms tps = 14.597315 (including connections establishing) tps = 14.597746 (excluding connections establishing)
実行結果を見ると、latency averageの行に1トランザクションあたりの実行時間が記載されているので、これを計測時間とします。
実験結果
INSERT
以下のSQLの実行速度を計測します。
今回はIDの生成にかかる時間は加味せずに計測したいので、IDは事前に作成してInsertします。
ULIDは本来は24桁ですが、UUID型のカラムに入れるためにCrockford’s Base32でエンコードして32桁にしたものを使用しています。(生成はこちらを参考にしました。)
INSERT INTO users (ID, name, age) VALUES
(XXX, 'あああ', 20),
...結果は以下になります。表示のため実行時間(ms)はlogを取っていますので、正確には棒グラフの数値を参照してください。
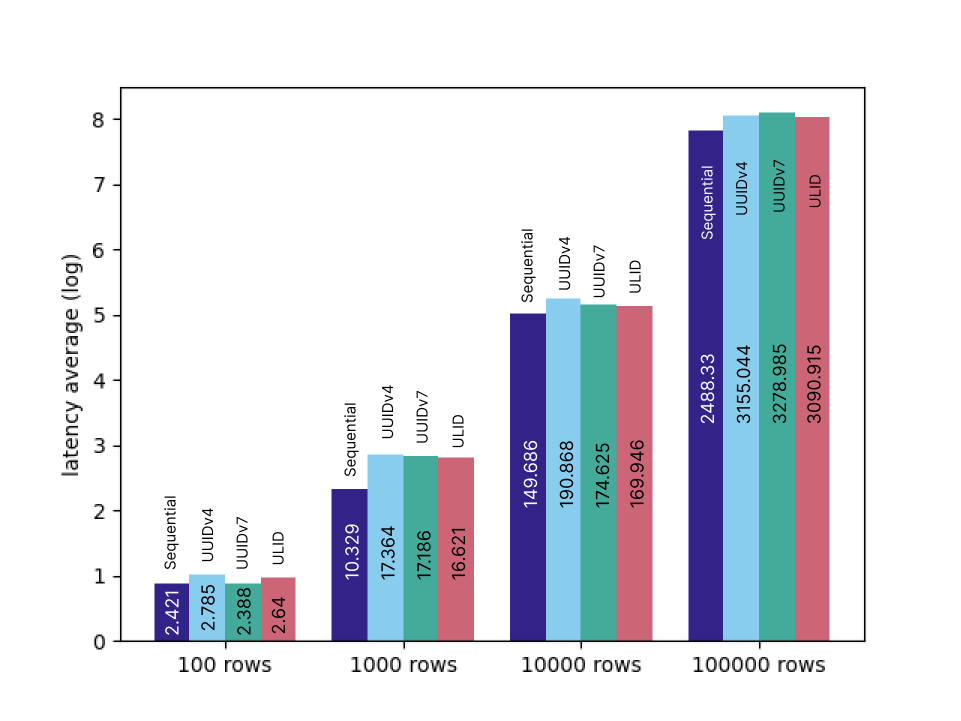
Sequential、ULIDの順にパフォーマンスがよさそうです。
UUIDv4は大体Sequentialの1.2倍程度の時間がかかっています。
ただし、実行時間の差は思ったより少なく、Insertがボトルネックになることはなさそうという印象でした。
SELECT
以下のSQLの実行速度を計測します。
SequentialとUUIDの比較をするためにORDER BY idを加えていますが、実際にはUUIDでソートすることはないと思われるので、あくまで実験的な結果になります。
※もし時系列でソートしたい場合はcreated_atなどでソートすることになると思いますが、その場合はcreated_atにindexを貼ればいいだけなのでUUIDでも問題はないと思います。
※ORDER BY idがない時はSeq Scanになるので、SequentialとUUIDで速度が変わることはないと思われます。
SELECT * FROM users ORDER BY id;結果は以下になります。表示のため、100rows以外の実行時間(ms)はlogを取っていますので、正確には棒グラフの数値を参照してください。

予想通り、Sequentialのパフォーマンスがよく、UUIDv4は悪く、UUIDv7とULIDはそれよりは良いという結果になりました。
SequentialはUUIDv4より実行時間が50パーセント近く少ないので、パフォーマンスにはかなり差があると言えそうです。
実際にはUUIDでソートすることは考えられないのでこの結果からSequentialなIDを選択する必要はないですが、値がランダムなカラムでソートするとかなり遅くなるということは覚えておきたいと思いました。
JOIN
UUIDをIDにすると大規模データ同士のJOINが遅いという話があります。
PostgreSQLで使われるJOINのアルゴリズムにはNested Loop Join, Hash Join, Merge Joinの3つがあります。
※参考までに、MySQLではNested Loop Joinのみのようです。
Joinの条件文に「<」があるときなどはNested Loop Joinしか使えない、Merge Joinは内部リレーションと外部リレーションの両方のデータが事前にソートされている必要があるなどの特徴があります。(参考)
今回は、EXPLAIN ANALYZEしてみると「Hash Right Join」が使われていました。
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------------
Aggregate (cost=574.26..574.27 rows=1 width=8) (actual time=41.927..41.937 rows=1 loops=1)
-> Hash Right Join (cost=368.00..549.26 rows=10000 width=0) (actual time=14.722..35.651 rows=10000 loops=1)
Hash Cond: (user_article_relations1.article_id = articles1.id)
-> Seq Scan on user_article_relations1 (cost=0.00..155.00 rows=10000 width=8) (actual time=0.015..6.731 rows=10000 loops=1)
-> Hash (cost=243.00..243.00 rows=10000 width=4) (actual time=14.551..14.554 rows=10000 loops=1)
Buckets: 16384 Batches: 1 Memory Usage: 480kB
-> Seq Scan on articles1 (cost=0.00..243.00 rows=10000 width=4) (actual time=0.007..7.126 rows=10000 loops=1)Joinが遅いと言っていた方もHash Joinだったので、Hash Joinでクエリが遅くなる理由を考えてみます。
Hash Joinでは生成したハッシュテーブルをメモリに保存する必要があります。
ハッシュ値のサイズは可変のようですので、UUID型はint型よりサイズが大きいためにハッシュテーブルのサイズも大きくなり、メモリに乗り切らないことが出てくるのかなと考えています。
以下のSQLの実行速度を計測します。
users, articles, user_article_relationsテーブルの行数は全て同じで、1人のユーザが1つのブログ記事を持っている想定です。
SELECT count(*)
FROM articles
LEFT JOIN user_article_relations on user_article_relations.article_id = articles.id
LEFT JOIN users on users.id = user_article_relations.user_id;結果は以下になります。表示のため実行時間(ms)はlogを取っていますので、正確には棒グラフの数値を参照してください。
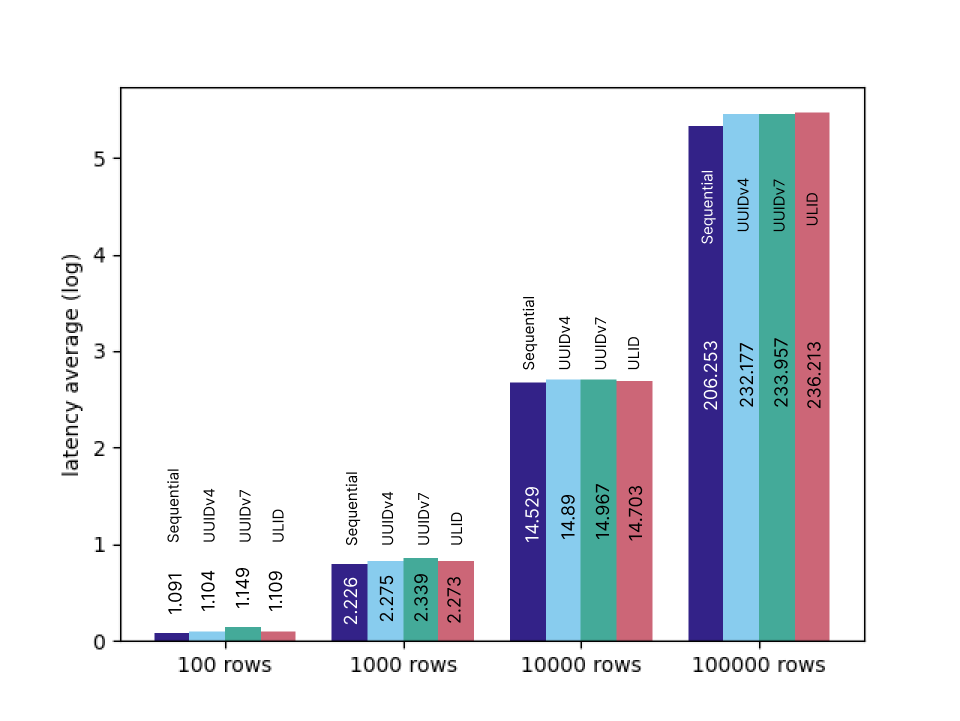
データが少ない時には実行時間にほとんど差はありませんが、10万行のJOINではSequentialの方が10数パーセント実行時間が短くなっています。
まとめ
SequentialなIDの方がパフォーマンスは良いものの、UUIDもそこまで遅くはないのでボトルネックにはならなさそうです。
同様に、ULIDもINSERTでの成績はUUIDより若干いいものの、パフォーマンスのためにUUIDではなくULIDを選択するほどではなさそうです。
UUIDv7かULIDかという観点で言えば、パフォーマンスは両者であまり変わらないので、より頑健なULIDを選択するのがベストかなと思いました。
UUIDをIDにするとMySQLだとかなりパフォーマンスが下がるようですが、今回の実験からはPostgresSQLではUUIDをIDにしても問題になる程のパフォーマンスの低下はないと言えます。
個人的にはJOINはUUIDはかなり遅いのではないかと思っていたので、あまり差がないのは意外でした。
異なる環境ではまた違う結果が出ると思うので、ぜひ皆さんもパフォーマンス計測してみてください!
参考
https://kakakakakku.hatenablog.com/entry/2022/10/31/082041
https://blog.daveallie.com/ulid-primary-keys
ttps://techblog.raccoon.ne.jp/archives/1627262796.html
https://mseeeen.msen.jp/postgresql-set-uuid-column-value-from-string/
https://severalnines.com/blog/overview-join-methods-postgresql/
Join our team!
ご覧いただきありがとうございました。テラドローンではエンジニアを募集しています!一緒にテラドローンで技術のアップデート・社会に役立つプロダクト開発を行っていきたい方
ぜひCasual Talk へ気軽にお申し込みください。
大石
ソフトウェアエンジニア。趣味は登山と読書です。
Golang / React